Neste artigo, será discutido o uso de fuzzing como técnica de testagem de software durante sua fase de desenvolvimento. Serão abordados desde o conceito de fuzzing, passando pelos seus tipos, exemplificando ferramentas e discutindo sua contribuição no cenário do processo de desenvolvimento de software. Por fim, mostraremos também que fuzzing não é a bala de prata que encontrará todos os erros de forma fácil, tendo limitações que requerem atenção no momento de sua implementação na esteira de desenvolvimento. Contudo, em conjunto com outras técnicas já estabelecidas, pode vir a acrescentar qualidade e robustez aos programas desenvolvidos e evitar falhas e vulnerabilidades que só viriam a ser descobertas no futuro, já no ambiente de produção.
Definição
A preocupação com a segurança dos códigos se tornou algo primordial em todos os setores da indústria nos últimos anos. Usualmente, avalia-se a qualidade de um programa apenas verificando que as entradas corretas proverão respostas precisas, mas é crucial realizar uma análise mais completa a fim de garantir que o programa é seguro contra ataques de entradas inválidas, aleatórias ou maliciosas. Nesse contexto, a técnica de testes fuzzing é utilizada tanto pela área de engenharia de software quanto pela de cibersegurança para melhorar a qualidade do código por meio da detecção semiautomatizada de erros em tempo de execução, que podem ou não representar vulnerabilidades de segurança.
O uso de testes fuzzing se difere dos testes unitários pela característica de que o último é composto por um conjunto limitado de entradas esperadas, focando em entradas que fazem sentido no contexto da aplicação, e testando partes pequenas e individualizadas do código, sendo executado de forma rápida (alguns segundos ou minutos no máximo). Já o fuzzing é empregado para testar uma enorme quantidade de parâmetros inesperados, que podem não ter sido planejados pelo desenvolvedor inicialmente. Assim, não faz parte da suíte de testes unitários, sendo que sua execução normalmente dura horas ou dias, podendo se estender indefinidamente. Dadas essas diferenças, ambas as técnicas podem e devem ser empregadas concomitantemente como forma de testar o código a ser desenvolvido.
Usos
Quando empregado para verificar a corretude de programas, o uso de fuzzing normalmente é acompanhado de uma forma de verificar o resultado em relação ao valor esperado. Por exemplo, quando estão sendo implementadas versões alternativas de protocolos ou algoritmos já conhecidos, tais como criptografia ou protocolos de rede, em que existem outros programas disponíveis que podem servir como base de comparação. Além disso, há também as aplicações em que o próprio contexto pode ser usado para verificar o resultado, como no caso da compressão lossless de arquivos, onde comprimir e descomprimir o arquivo em sequência deve garantir que o mesmo resultado seja obtido.
Já no contexto de verificação de segurança, fuzzing é considerada hoje a melhor técnica para encontrar problemas de forma barata e eficiente. Com um pequeno trabalho de configuração inicial, é possível executar milhões de testes e encontrar defeitos nas partes mais escondidas dos programas onde outras técnicas, tais como etapa de testes de Quality Assurance (QA) ou revisão de código, não são tão eficientes. Ferramentas de fuzzing focadas nesse contexto se proliferaram na última década, tendo hoje diversas opções gratuitas e de código aberto para serem utilizadas.
Tipos e ferramentas
As técnicas de fuzzing são divididas em categorias, de forma que ferramentas normalmente se enquadram em uma dessas:
- Generation-based fuzzing: A ferramenta utiliza um template de como o arquivo de teste é estruturado para gerar novos casos.
- Mutation-based fuzzing: Funciona a partir da modificação de arquivos de exemplo passados à ferramenta.
- Guided fuzzing: Extensão de Mutation-based fuzzing. Há um loop de feedback durante o teste de novos casos, de forma que a ferramenta saberá se a nova entrada gerada causou um avanço na cobertura do código analisado. Os fuzzers mais famosos se enquadram nessa categoria: libFuzzer, AFL, AFL++, Honggfuzz. A Figura 01 mostra uma representação de como esse tipo de ferramenta normalmente é implementada.
- Snapshot fuzzing: Utiliza emuladores para melhorar performance e aumentar o determinismo do fuzzing.
- Modular fuzzing: separa-se o código da aplicação a ser testada, de forma a verificar apenas uma parte isolada dessa.
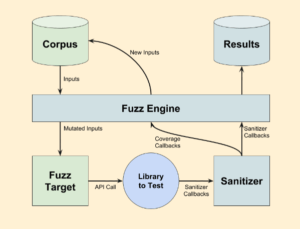
(Figura 1)
Uma das ferramentas mais simples, mas ao mesmo tempo eficiente, é o Radamsa. Esse gerador de casos de teste, na categoria de Mutation-based fuzzers, realiza apenas a tarefa de modificar uma entrada original de forma aleatória, para ser posteriormente utilizada como entrada no programa testado. A facilidade de utilização dessa ferramenta por intermédio do terminal a torna uma ótima candidata para testar aplicações de linha de comando (CLI), necessitando apenas da escrita de um simples script, de forma que o programador gasta pouco tempo e não precisa de conhecimento profundo da ferramenta para utilizá-la corretamente. Contudo, diferente de outros fuzzers, que discutiremos a seguir, o Radamsa não utiliza um loop de feedback, assim, em nenhum momento a eficiência das entradas que estão sendo testadas é verificada, tornando o processo aleatório. Apesar de isso tornar a ferramenta mais performática, ao mesmo tempo que pode ser empregada de forma natural em cenários de blackbox (quando não há acesso ao código fonte da aplicação), também significa que o Radamsa não é a melhor ferramenta para testar programas mais complexos que apresentam muitos fluxos de código com condicionais não triviais.
Já na categoria de guided fuzzing, destaca-se o American Fuzzy Lop (AFL) e seus forks, mais predominantemente o AFL++. Essa ferramenta possui seu próprio compilador personalizado, que pode ser usado para compilar o programa testado, de forma a adicionar trechos extras de código que são usados durante o teste para entender melhor o fluxo do programa e descobrir se as entradas modificadas estão exercitando o código de maneira eficiente. Esse tipo de técnica portanto tende a apresentar resultados melhores, pois foca-se em entradas que levam à execução de partes diferentes do código, exercitando-o com maior completude. Contudo, suas desvantagens incluem baixa performance e a necessidade de possuir o código fonte da aplicação, além de que esse seja compilável com as ferramentas disponibilizadas, o que nem sempre é possível em projetos mais complexos ou antigos. A Figura 02 apresenta a execução do AFL++ em uma aplicação, onde foram encontrados em cinco minutos dois bugs que causaram falha na execução do programa.
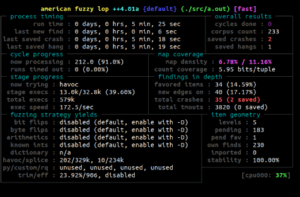
(Figura 2)
Um tipo de teste que tem ganhado destaque recentemente é o snapshot fuzzing. Nele, utiliza-se de emuladores para melhorar a performance e determinismo dos testes, principalmente por meio da emulação das chamadas de sistema, diminuindo a quantidade de trocas de contexto para o kernel, o que reduz significativamente o overhead e melhora as oportunidades de paralelismo. O termo snapshot vem do fato de que, antes do início do loop de testes, é feita a cópia da imagem do processo já em um estado avançado, por exemplo após o início da execução da função main, depois de feito todo o carregamento e setup pelo sistema operacional e suas bibliotecas. A entrada é então modificada em memória, e prossegue-se com o teste. Ao final, retorna-se ao snapshot, modificando o input de outra forma, em loop. Isso evita uma grande quantidade de chamadas de sistema desnecessárias, como mmap, execve e fork. Pode parecer contraintuitivo utilizar emuladores para aumentar a performance, mas a ideia está no fato de que os programas testados normalmente fazem muitas chamadas de sistema (alocação de memória, leitura de arquivos, criação do processo, etc), o que diminui muito a velocidade do fuzzing, devido ao alto custo computacional durante a troca de contexto. Devido às especificidades que a técnica traz, essa categoria normalmente é representada por ferramentas especialmente criadas para testar um único programa ou um tipo de programa específico, não tendo nenhuma ferramenta de propósito geral amplamente disponível para uso. Um exemplo seria o what the fuzz (wtf).
Limitações
Contudo, o emprego da técnica no cenário de segurança não é garantia de encontrar todos os tipos de vulnerabilidades existentes. Normalmente, fuzzing pode ser empregado para encontrar erros relacionados a leitura e escrita ilegal na memória, o que normalmente acontece em programas escritos em linguagens de mais baixo nível como C, C++, e Assembly. Outra utilidade é encontrar problemas de negação de serviço (DoS), identificando entradas que podem causar loops infinitos ou um elevado tempo de execução.
Erros relacionados à lógica de negócio do programa são mais difíceis de identificar por meio de fuzzing, pois seria necessário que a ferramenta fosse capaz de reconhecer resultados incorretos que não causam erros fatais. Nesse cenário, um desenvolvedor poderia distinguir as características comuns a um resultado correto, por exemplo o fluxo de código esperado, ou invariantes que o resultado correto sempre irá respeitar, e desenvolver um fuzzer personalizado que verifica essas características para identificar possíveis erros de lógica.
Além disso, as ferramentas disponíveis hoje para a realização de fuzzing costumam focar em testes de propósito geral. Dessa forma, situações diferentes dos cenários mais comuns, como leitura da entrada a partir da rede ao invés de arquivos, ou entradas que possuem uma estrutura específica que é verificada de alguma forma, tal como pacotes de rede que são acompanhados de um checksum, podem acarretar em o fuzzer não conseguir criar entradas que ultrapassem essas verificações, e não exercitar o código por completo. Nesses casos, a melhor opção é a escrita de um fuzzer personalizado para aquela aplicação específica, o que pode ser feito tanto do zero quanto a partir da modificação de ferramentas já existentes. Outra opção é modificar o código fonte da aplicação testada, caso esse esteja disponível, para remover as verificações ou modificar a forma como a entrada é recebida, facilitando assim os testes.
Conclusão
Com isso, é possível perceber que testes fuzzing são uma técnica muito útil no processo de desenvolvimento de software com o objetivo de encontrar falhas de programação. No entanto, eles ainda não são usados extensivamente nos projetos, principalmente devido à falta de conhecimento em relação aos seus benefícios e à dificuldade de adaptar as ferramentas disponíveis para a realização de testes em programas mais específicos, onde testes unitários e de integração já demonstraram seus benefícios com um baixo custo técnico. Como já discutido, as técnicas de testagem devem ser vistas como complementares, e não exclusivas, de forma a melhorar a confiança na qualidade e segurança do software.